
Are Data Silos Quietly Undermining Your Growth Strategy?
Most enterprises are sitting on enormous amounts of data — from ERP systems, IoT devices, CCTV feeds, retail operations, logistics networks, and customer platforms — yet much of it remains trapped in disconnected environments. At Dtonic, we see this challenge repeatedly across smart cities, retail, manufacturing, and public-sector transformation programs.
In virtually every data and AI conversation happening inside enterprise organizations today, one challenge comes up time and again: organizations are sitting on enormous amounts of data, yet much of it is effectively invisible — trapped inside different systems, different business units, and different platforms. Each of those technology decisions was reasonable at the time. But collectively, they've created an environment where getting a clear, unified picture of the business is far harder than it should be.
This is the data silo problem. And while the term is familiar, its true cost is consistently underestimated — not just in operational efficiency, but in strategic agility, decision quality, and the ability to unlock AI and advanced analytics at scale.
The Landscape Most Organizations Actually Live In
In operational environments, the problem becomes even more severe. A city may run parking, traffic, safety, and citizen-service systems separately. A retailer may separate pricing, inventory, footfall, and promotion data. A factory may isolate sensor data from planning systems. The result is delayed decisions in environments where real-time action matters.
When you look inside a typical large enterprise — whether retail, healthcare, or financial services — the picture tends to be recognizable. There's usually a core data warehouse, perhaps a legacy on-premises system that's been in place for years. Around that sits a data lake that arrived more recently as part of cloud migration. Multiple BI platforms coexist. A streaming layer was introduced for one specific use case. And running underneath it all are a collection of pipelines — some built in modern orchestration tools, some in older scripting languages, and some that only one or two people in the organization fully understand.
The immediate symptoms are equally familiar: reports that take too long to produce, different teams arriving at different numbers for the same metric, data quality that varies depending on which system you query, and a business that waits weeks for an analytics capability that should take days.
The root cause is rarely the dashboard itself. It is usually the absence of an operational data architecture capable of connecting legacy systems, streaming data, enterprise applications, and AI workloads into one governed environment.
But the deeper issue is strategic. Organizations operating in a fragmented state spend the majority of their data team's capacity on integration, maintenance, and reconciliation — rather than generating the insights and business value that justify the investment in the first place.
Why Fragmentation Is So Hard to Diagnose
What makes the data silo problem particularly insidious is that it rarely presents itself as what it is. Business leaders typically frame it as a reporting problem, or a speed-to-insight problem, or a data quality problem. Those things are real. But when you start pulling on the thread — asking where the data comes from, how it gets transformed, who owns it, which teams consume it — you almost always arrive at architectural fragmentation as the underlying cause.
The impact becomes even clearer in operational environments. In smart city programs, fragmentation often means parking systems cannot communicate with traffic systems, CCTV data cannot support incident response, and planners lack a unified view of city operations. In defense and security environments, the stakes are higher: sensor feeds, command systems, surveillance data, and operational intelligence remain separated across platforms, slowing situational awareness and coordinated response. Data silos do not just reduce efficiency — they reduce responsiveness.
A common pattern: an organization has two or three data streams, each supporting a different business unit, each running its own pipelines and maintaining its own data stores. When a business leader asks for a cross-functional view — say, combining commercial performance with operational data — it becomes a significant engineering project just to assemble the inputs. By the time the report is produced, the data is already stale.
Another pattern: different teams have built their own definitions of core business metrics — revenue, customer count, retention rate. These should be unambiguous, shared definitions. In fragmented environments, it's common to find three or four versions of the same metric being reported in different ways by different teams. Once confidence in data is eroded, it is genuinely hard to rebuild.
What a Well-Executed Migration Actually Looks Like
In our experience, successful modernization is rarely a dramatic platform replacement. It is a phased transformation where organizations prioritize high-value use cases first, prove measurable outcomes, and expand from there without disrupting live operations.
Attempting to move an entire data estate into a new environment in a single program means asking the organization to simultaneously change its data platform, its ways of working, its governance model, and its team structure. The risk of disruption is extremely high, and value doesn't materialize until everything is done — which could be 18 months or two years away.
Key Insight: The approach that consistently works is phased and value-led: identify the workloads in most pain or where a unified approach would unlock the most immediate value, set up the environment correctly from day one, demonstrate outcomes, and use that foundation for the next phase.
This approach accomplishes two things simultaneously. First, it de-risks the program — the organization learns and adapts as it goes rather than committing everything up front. Second, it generates visible results early, which builds confidence in leadership and creates momentum in the data team.
The Four Foundations That Determine Success
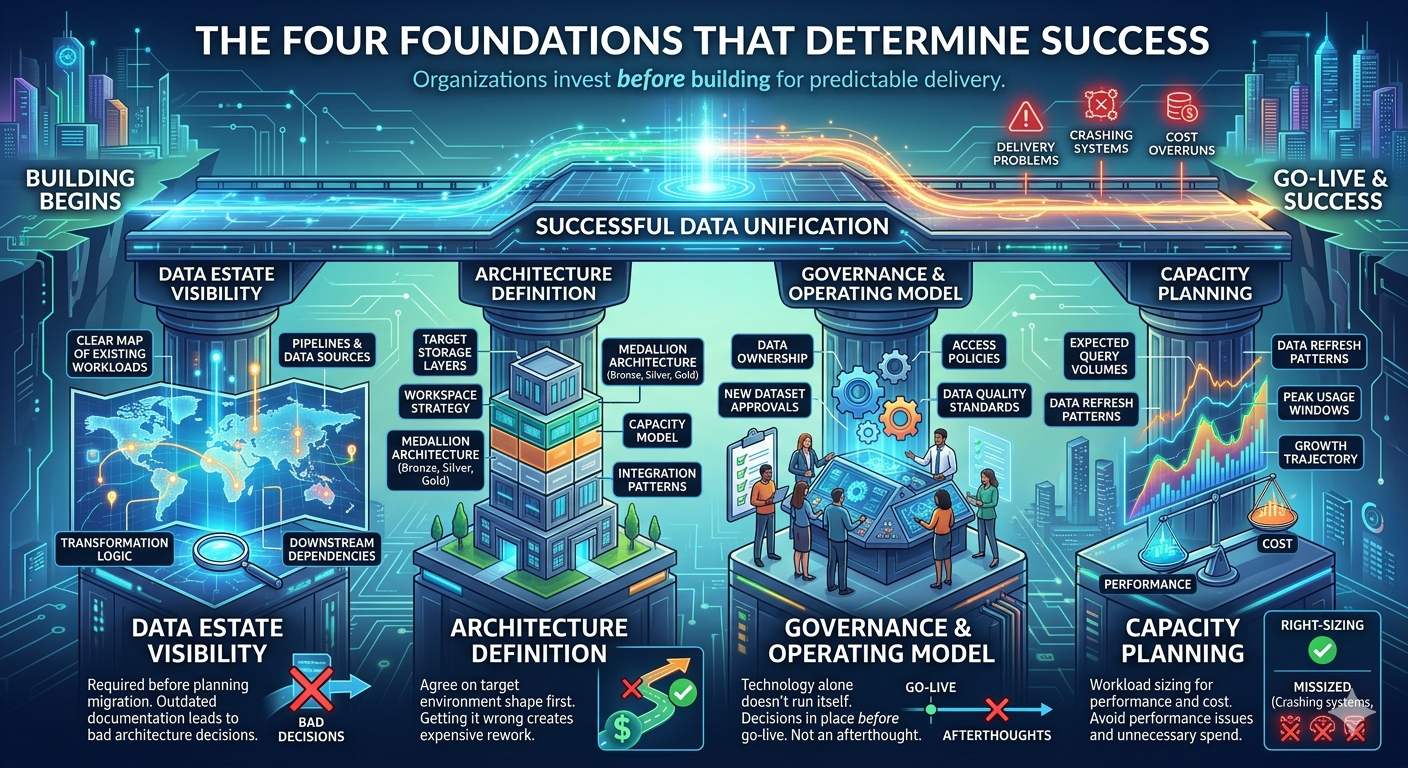
Organizations that execute well on data unification have consistently invested in four critical areas before they begin building. When any one of these is underdeveloped, it typically surfaces as a delivery problem later.
Data estate visibility. Before planning a migration, you need a clear map of what you're migrating — existing workloads, pipelines, data sources, transformation logic, and downstream dependencies. In many organizations this documentation either doesn't exist or is out of date. You genuinely can't make good architecture decisions without it.
Architecture definition. The shape of the target environment — its storage layers, workspace strategy, medallion architecture, capacity model, and integration patterns — needs to be agreed upon before building begins. These decisions have a long tail. Getting them wrong early creates expensive rework later.
Governance and operating model. Technology alone doesn't run itself. Clear decisions are needed about who owns data, who approves new datasets as they arrive, how access policies are managed, and how data quality standards are enforced. These decisions should be in place before go-live — not treated as an afterthought.
Capacity planning. Workload sizing matters for both performance and cost management. Understanding expected query volumes, data refresh patterns, peak usage windows, and growth trajectory allows right-sizing from the start — avoiding both performance issues and unnecessary spend over time.
What Changes Once You Get There
For organizations that have gone through the transition thoughtfully and successfully unified their data estate, the impact tends to be felt across three dimensions — and they compound on each other over time.
Operational Simplification: Teams managing four or five separate platforms consolidate into one governed environment. The overhead of running the data infrastructure itself reduces significantly, freeing engineers to build rather than maintain.
Analytics Agility: When data engineering, warehousing, and reporting are deeply integrated, cycle time from data ingestion to business insight shortens dramatically. New data sources onboard faster. The reconciliation problem disappears — there is one version of truth, accessible to everyone who needs it.
AI Readiness: Meaningful AI initiatives — predictive models, large-scale automations, intelligent analytics — all require a well-governed, unified, high-quality data foundation. Once that foundation is in place, AI capabilities become genuinely accessible rather than perpetually aspirational.
The AI readiness point is strategically significant, because it reframes the business case in a way that resonates at the leadership level. Consolidation matters internally to the data team. But the idea that a unified data estate is a prerequisite for executing an AI strategy is a conversation that lands at the board level — and for organizations that have AI as a strategic priority, it fundamentally changes how the investment is evaluated.
The Human Side of the Transition
One dimension that consistently doesn't get enough attention is the people side of this change. Migrating a data estate means asking individuals to change how they work — data engineers who have spent years building pipelines in familiar toolsets, BI developers who know every nuance of the existing reporting environment, data stewards who have built governance processes around the current tools.
Organizations that handle this well do three things consistently. They involve the data team early — not as recipients of a decision that has already been made, but as participants in the architecture and design process. They invest seriously in enablement through sustained capability building, hands-on workshops, and dedicated time to develop skills on the new platform. And they establish visible internal champions — people within the data team who are genuinely enthusiastic about the new platform and can bring colleagues along with them. Peer advocacy is far more effective than top-down mandates when it comes to driving adoption.
Organizations that shortcut the people dimension typically see adoption plateau after go-live. Teams revert to familiar tools, workarounds emerge, and the full potential of the new platform is never realized.
The organizations winning with data right now are not necessarily the ones with the largest data teams or the most significant technology spend. They are the ones who made a deliberate architectural choice to build a clear, governed, unified data foundation — and built everything on top of it.
Data silos are not just a technical constraint — they are a compounding one
Every day that a fragmented architecture remains in place, the cost accumulates: wasted team capacity, missed insights, slow decisions, and a widening gap between where the organization is and where it wants to be with its data and AI. The challenge is real, the cost is real, and the path to addressing it is clear — but it requires investment, planning, and sequencing.
For organizations that take it seriously and approach the transition with the right foundation, the result is a data capability that genuinely changes the way they do business.
How D.Hub 2.0 Solves the Problem
D.Hub 2.0 is designed for exactly this challenge: helping enterprises move from fragmented systems to an integrated AI data foundation.
Instead of adding another disconnected tool, D.Hub 2.0 enables organizations to unify and operationalize data across environments.
Key Capabilities
Unified Data Integration
Connect cloud, on-premise, IoT, sensor, video, ERP, CRM, and legacy systems into one governed architecture capable of supporting both operations and analytics.Real-Time & Batch Processing
Support both historical analytics and live operational intelligence.Governance by Design
Lineage, ownership, access control, metadata, and policy management built into the platform.AI-Ready Foundation
Transform fragmented enterprise data into trusted AI context for LLMs, predictive models, intelligent agents, computer vision, and operational automation.Scalable Enterprise Architecture
Designed for smart cities, retail, manufacturing, finance, and public-sector environments where complexity is the norm.
What Transformation Looks Like
Organizations that modernize with a unified data architecture typically move from reactive operations to intelligent operations.
Faster reporting cycles
One trusted version of truth
Lower platform complexity
Improved cross-functional visibility
Faster deployment of AI use cases
Stronger decision-making confidence
This is not just operational improvement. It is a shift in competitiveness.
The Real Question for Leaders
The issue is rarely whether your organization has enough data. The real question is:
“Can your data architecture support growth, speed, and AI at enterprise scale?”
If the answer is unclear, it may be time to reassess the foundation.